基于Ajax+Lucene构建搜索引擎的设计与实现
摘 要
通过搜索引擎从互联网上获取有用信息已经成为人们生活的重要组成部分,Lucene是构建搜索引擎的其中一种方式。搜索引擎系统是在.Net平台上用C#开发的,数据库是MSSQL Server 2000。主要完成的功能有:用爬虫抓取网页;获取有效信息放入数据库;通过Lucene建立索引;对简单关键字进行搜索;使用Ajax的局部刷新页面展示结果。
论文详细说明了系统开发的背景,开发环境,系统的需求分析,以及功能的设计与实现。同时讲述了搜索引擎的原理,系统功能,并探讨使用Ajax与服务器进行数据异步交互,从而改善现有的Web应用模式。
关键词:Lucene.net;异步更新;Ajax;搜索引擎
The Design and Implementation for Constructing the Search Engine with Ajax and Lucene
Abstract
Obtaining useful information from web by search engines has become the important part of people's lives. Lucene is the way of constructing search engine. This system is based on the .Net platform using C#. The database is MSSQL Server 2000. Main functions are grasping web pages with crawls, adding effective information to the database, establishing index with Lucene, searching through keywords, and displaying the results finally.
This paper has showed the principle of search engine in the form of different modules, functions of this system, improving traditional web application model using Ajax. It shows explanation of the system’s background, development environment, system analysis of demanding, and functions of design.
Key words: Lucene.net; Asynchronous update; Ajax; Search engines
目 录
论文总页数:19页
1 引言
1.1 课题背景
Lucene是一个基于Java的全文信息检索工具包,它为应用程序提供索引和搜索功能。Lucene目前是Apache Jakarta家族中的一个开源项目。也是目前最为流行的基于Java开源全文检索工具包。Lucene是Java世界中常用的索引API,使用它提供的方法可以为文本资料创建索引,并提供检索。Lucene.net它只在命名方面采纳了.Net的建议,主要目标倾向于和Java Lucene兼容:一个是索引格式兼容,达到可以共同工作的目的;一个是命名接近(只相差很少,比如大小写等),目的是可以方便开发者使用Java Lucene相关的代码和资料。
1.2 国内外研究现状
国内外对搜索引擎研究比较著名的便是Google了。无论搜索技术本身还是搜索范围与深度,Google搜索总是所有搜索引擎的目标。Google专业领域搜索方面做的成效是有目共睹的。Google在低层次的智能搜索方面已经开始研究很多年了,实际的成果就是翻译方面。利用搜索技术,加上经验主义发展出来的Google翻译机器人,在外语翻译方面已经比传统的翻译好很多了。但是翻译仅仅是学术方面的应用,更重要的是Google建立起来的海量搜索历史记录。如果把这些海量搜索历史记录当作是词典的话,那么如果与搜索技术的结合发展成为低层次的只能搜索,那么应用就将大大加强与广泛。
国内,对搜索引擎的专注和对中文的理解能力也是中国本土搜索引擎行业独特的竞争力。国内比较著名的比如百度,更专注对中文的处理。中文的意思多种多样,是很难用程序处理的。目前国内外都在做中文引擎,门户网站、非门户网站也都在进军搜索业,成立搜索门户。为了满足用户更深层次的需求,国内的搜索引擎也在不断的完善自己。如何将人类的知识和智能加入到检索中,如何使搜索引擎的质量产生一个质的飞跃,也是国内搜索引擎努力的方向。中国网民对智能化搜索需求也是显而易见的。这也意味着搜索不再是简单的技术或者是网络导航而已,而是会成为普通人生活中必备的工具之一。
1.3 本课题研究的意义
随着计算机技术和互联网技术的飞速发展,网络上的信息量急剧增长,要在浩如烟海的网络世界中寻找需要的信息,作为现代信息获取技术的主要应用,那么搜索引擎是必不可少的。通过Lucene.net,可以很方便的构建起搜索引擎,本毕业设计除了考查使学生综合运用以前所学知识的能力,同时也使学生了解当今搜索及编程的一些新技术,并模拟简单的搜索引擎开发。
1.4 本课题的研究方法
在本系统的开发过程中,首先分析了搜索引擎的相关功能,写出需求分析;其次,综合运用以前所学的相关知识(数据库,C#等),选择所熟悉的开发工具进行开发(本系统选择了Microsoft Visual Studio .NET 2003作为开发平台,开发语言选择了C#;数据库采用Microsoft SQL Server 2000)。由于Lucene不是完整的搜索引擎程序,只为搜索引擎应用提供了工具包,在Asp.net平台中,可使用Lucene.net这个对Lucene兼容的库。使用Lucene.net协助完成搜索引擎相关的网页爬虫与抓取,为文档建立索引,关键词搜索的功能,通过Ajax优化系统,完成页面的局部刷新功能,给用户好的体验。
2 Lucene.net构建搜索引擎原理
2.1 全文搜索引擎
2.1.1 搜索引擎的分类
获得网站网页资料,能够建立数据库并提供查询的系统,我们都可以把它叫做搜索引擎。真正意义上的搜索引擎,通常指的是收集了因特网上几千万到几十亿个网页并对网页中的每一个词(即关键词)进行索引,建立索引数据库的全文搜索引擎。当用户查找某个关键词的时候,所有在页面内容中包含了该关键词的网页都将作为搜索结果被搜出来。在经过复杂的算法进行排序后,这些结果将按照与搜索关键词的相关度排列。按照工作原理的不同,可以把它们分为两个基本类别:全文搜索和分类目录。
全文搜索引擎通过从互联网上提取的各个网站的信息(以网页文字为主)而建立的数据库中,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户。从搜索来源的角度,全文搜索引擎又可细分为两种,一种是拥有自己的检索程序(Indexer),俗称“蜘蛛”(Spider)程序或“机器人”(Robot)程序,并自建网页数据库,搜索结果直接从自身的数据库中调用;另一种则是租用其他引擎的数据库,并按自定的格式排列搜索结果。
分类目录则是通过人工的方式收集整理网站资料形成数据库的,比如雅虎中国以及国内的搜狐、新浪、网易分类目录。另外,在网上的一些导航站点,也可以归属为原始的分类目录。
2.1.2 搜索引擎的工作原理
搜索引擎的原理,可以看作三步:从互联网上抓取网页,建立索引数据库,在索引数据库中搜索。
全文搜索引擎的 “网络蜘蛛”能够扫描一定地址范围内的网站,并沿着网络上的链接从一个网页到另一个网页,从一个网站到另一个网站采集网页资料。它为保证采集的资料最新,还会回访已抓取过的网页。网络机器人或网络蜘蛛采集的网页,还要有其它程序进行分析,根据一定的相关度算法进行大量的计算建立网页索引,才能添加到索引数据库中。我们平时看到的全文搜索引擎,实际上只是一个搜索引擎系统的检索界面,当你输入关键词进行查询时,搜索引擎会从庞大的数据库中找到符合该关键词的所有相关网页的索引,并按一定规则呈现给我们。不同的搜索引擎,网页索引数据库不同,搜索结果也就不尽相同。
利用能够从互联网上自动收集网页的Spider程序,自动访问互联网,并沿着网页中的所有URL爬到其它网页,重复这过程,并把爬过的所有网页收集回来。然后建立索引数据库,由分析索引程序对收集回来的网页进行分析,提取相关网页信息(包括网页所在URL、编码类型、页面内容包含的关键词、关键词位置、生成时间、大小、与其它网页的链接关系等),然后用这些相关信息建立网页索引数据库。接下来在索引数据库中搜索排序,当用户输入关键词搜索后,由搜索系统程序从网页索引数据库中找到符合该关键词的所有相关网页。最后,由页面生成系统将搜索结果的链接地址和页面内容摘要等内容组织起来返回给用户。搜索引擎只能搜到它网页索引数据库里储存的内容。
2.2 Lucene与搜索引擎
Lucene是一个全文信息检索工具包,为应用程序提供索引和搜索功能。和Java Lucene兼容的Lucene.net可以用在.net平台。Lucene能够为文本类型的数据建立索引,所以你只要能把你要索引的数据格式转化的文本的,Lucene就能对你的文档进行索引和搜索。比如你要对一些HTML文档,PDF文档进行索引的话你就首先需要把HTML文档和PDF文档转化成文本格式的,然后将转化后的内容交给Lucene进行索引,然后把创建好的索引文件保存到磁盘或者内存中,最后根据用户输入的查询条件在索引文件上进行查询。不规定要索引的文档的格式也使Lucene能够适用于几乎所有的搜索应用程序。
如图1表示了搜索应用程序和Lucene之间的关系,也反映了利用Lucene构建搜索应用程序的流程:
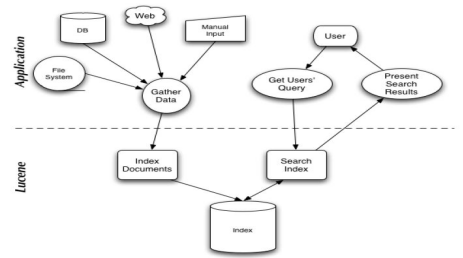
图1 应用程序和Lucene
2.3 索引和搜索
索引是现代搜索引擎的核心,建立索引是把数据源处理成非常方便查询的索引文件的过程。为什么索引这么重要呢,试想你现在要在大量的文档中搜索含有某个关键词的文档,那么如果不建立索引的话你就需要把这些文档顺序的读入内存,然后检查这个文章中是不是含有要查找的关键词,这样的话就会耗费非常多的时间,想想搜索引擎可是在毫秒级的时间内查找出要搜索的结果的。这就是由于建立了索引的原因,你可以把索引想象成这样一种数据结构,他能够使你快速的随机访问存储在索引中的关键词,进而找到该关键词所关联的文档。Lucene采用的是一种称为反向索引(inverted index)的机制。反向索引就是说我们维护了一个词/短语表,对于这个表中的每个词/短语,都有一个链表描述了有哪些文档包含了这个词/短语。这样在用户输入查询条件的时候,就能非常快的得到搜索结果。我们将在本系列文章的第二部分详细介绍Lucene的索引机制,由于Lucene提供了简单易用的API,所以也可以非常容易的使用Lucene对文档实现索引的建立。
对文档建立好索引后,就可以在这些索引上面进行搜索了。搜索引擎首先会对搜索的关键词进行解析,然后再在建立好的索引上面进行查找,最终返回和用户输入的关键词相关联的文档。
2.4 Ajax技术
Ajax全称为“Asynchronous JavaScript and XML”(异步JavaScript和XML),是指一种创建交互式网页应用的网页开发技术。Ajax技术是目前在浏览器中通过JavaScript脚本可以使用的所有技术的集合。包括:HTML和CSS,使用文档对象模型DOM作动态显示和交互,使用XML做数据交互和操作,使用XMLHttpRequest进行异步数据接收,使用JavaScript将它们绑定在一起。
Ajax技术之中,核心的技术就是XMLHttpRequest,它最初的名称叫做XMLHTTP,是微软公司为了满足开发者的需要,1999年在IE5.0浏览器中率先推出的。后来这个技术被上述的规范命名为XMLHttpRequest。它正是Ajax技术之所以与众不同的地方。简而言之,XMLHttpRequest为运行于浏览器中的JavaScript脚本提供了一种在页面之内与服务器通信的手段。页面内的JavaScript可以在不刷新页面的情况下从服务器获取数据,或者向服务器提交数据。XMLHttpRequest的出现为Web开发提供了一种全新的可能性,甚至整个改变了人们对于Web应用由什么来组成的看法。它可以使我们以一种全新的方式来做Web开发,为用户提供更好的交互体验。
传统的web应用模型如图2:
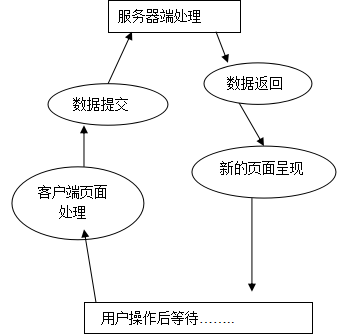
图2 Web应用模型
与传统的Web开发不同,Ajax并不是以一种基于静态页面的方式来看待Web应用的。从Ajax的角度看来,Web应用应由少量的页面组成,其中每个页面其实是一个更小型的Ajax应用。每个页面上面都包括有一些使用JavaScript开发的Ajax组件。这些组件使用XMLHttpRequest对象以异步的方式与服务器通信,从服务器获取需要的数据后使用DOM API来更新页面中的一部分内容。因此Ajax应用与传统的Web应用的区别主要在三个地方:
1. 不刷新整个页面,在页面内与服务器通信。
2. 使用异步方式与服务器通信,不需要打断用户的操作,具有更加迅速的响应能力。
3. 系统仅由少量页面组成。大部分交互在页面之内完成,不需要切换整个页面。
由此可见,Ajax使得Web应用更加动态,带来了更高的智能,并且提供了表现能力丰富的Ajax UI组件。
3 需求分析
3.1 同步环境
本系统的同步环境如图3:

图3 同步环境
检索服务器通过Internet检索Web页面。
3.2功能需求
本设计要实现的功能:
- 能够对Internet上的网页内容、标题、链接等信息按链式收集。
- 能够实现一定链接深度的网页收集,也就是在Internet上实现一定的URL级的数据收录。
- 对收集到的数据存入MSSQL Server 2000等关系型数据库中、或者存入文本文件中。
- 网站信息库中的信息会不断的变动,对收集到的数据需要定期的自动维护,做到定期的删除、从新收集。
- 对收集到的数据进行关键词的检索。
- 对检索出的数据要可定位性,即可以显示对数据的出处的链接。
- 实现中英文分词功能,能够按中文或者英文单词检索数据。
- 实现无刷新的显示搜索结果,对搜索用时的计算、显示,关键字高亮显示等。
- 逻辑搜索功能比如“中国”AND“北京”AND NOT(“海淀区”AND“中关村”)。
3.3 性能需求
- 精度:
1.1对收集到的信息需要一定的完整性,即对链接层次里的每个链接页面都能够收集得到,并写入收集的存储区里。
1.2对搜索出的内容需要包含有关键字信息
- 时间特性要求:
2.1数据收集时,因为是对Internet网上Web信息的收集,并且采用URL级链式的网页收集。收集数据时不能够出现无响应的等待。
2.2搜索时响应时间应不超过3秒,无论搜索的记录多少。
- 灵活性
3.1具有良好的中文切词功能。
3.4 输入输出要求
输入:搜索的关键字。
处理:去前后空格,关键字,查询索引库。
输出:Web页面上显示搜索信息。
3.5 运行需求
1.硬件环境需求:
需要使用专用服务器,P4以上,512M以上内存,80G以上硬盘;Internet网络连接。
2.软件环境:
源端:Windows 2003/XP操作系统、MSSQL Server 2000数据库、IIS5.0、.NET Framework1.1。
4 方案设计
结合前面的同步原理,以及需求的介绍,下面给出同步的方案设计。
4.1 搜索引擎模型
模型包括爬虫、索引生成、查询以及系统配置部分。爬虫包括:网页抓取模块、网页减肥模块、爬虫维持模块。索引生成包括:基于文本文件的索引、基于数据库的索引。查询部分有Ajax、后台处理、前台界面模块。如图4所示。
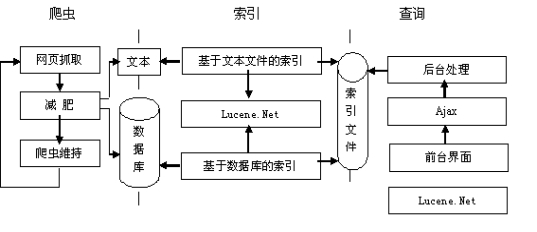
图4 系统模块
4.2 数据库的设计
本课题包含一张用于存放抓取回来的网页信息如表1。
表1 网页数据存储表
|
逻辑字段名 |
物理字段名 |
字段类型 |
是否为空 |
主键 |
外键 |
说 明 |
|
编号 |
ID |
int |
NOT NULL |
Yes |
|
自增加 |
|
地址 |
Url |
Varchar(50) |
NOT NULL |
|
|
|
|
内容 |
Content |
VARCHAR(1000) |
NOT NULL |
|
|
|
|
meta标签内容 |
Mata |
Varchar(100) |
NOT NULL |
|
|
|
|
网页标题 |
Title |
Varchar(100) |
NOT NULL |
|
|
|
|
创建时间 |
Createdate |
Datetime(8) |
NOT NULL |
|
|
|
4.3 模块设计
该模型按照功能划分为三个部分,一是爬虫抓取网页部分,二是从数据库建立索引部分,三是从前台页面查询部分。系统的功能流程(如图5.1和5.2)。

图5.1 功能流程图
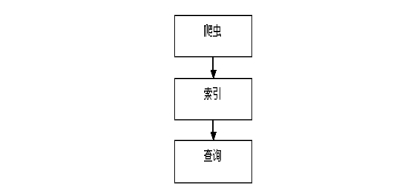
图5.2 模块图
该系统用3个模块来实现搜索引擎的主要功能。流程如上图所示。
从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。这条件可以是限定的谋个域名空间、或者是限定的网页抓取级数。当在获取URL时存在这样的问题就是在实际应用中主要以绝对地址和相对地址来表现。绝对地址是指一个准确的、无歧义的Internet资源的位置,包含域名(主机名)、路径名和文件名;相对地址是绝对地址的一部分。然后把抓取到的网页信息包括网页内容、标题、链接抓取时间等信息经过‘减肥’后保存到网页存储数据库表里。然后通过正则表达式,去掉多余的HTML标签。因为抓取的网页含有HTML标签、Javascript等,对搜索多余的信息,如果抓取到的网页不经过处理就会使搜索变得不够精确。
让爬虫程序能继续运行下去,就得抓取这个网页上的其它URL,所以要用正则将这个网页上的所有URL都取出来放到一个队列里。用同样的方法继续抓取网页,这里将运用到多线程技术。
为了对文档进行索引,Lucene提供了五个基础的类,他们分别是Document,Field,IndexWriter,Analyzer,Directory Document是用来描述文档的,这里的文档可以指一个HTML页面,一封电子邮件,或者是一个文本文件。一个Document对象由多个Field对象组成的。可以把一个Document对象想象成数据库中的一个记录,而每个Field对象就是记录的一个字段。在一个文档被索引之前,首先需要对文档内容进行分词处理,这部分工作就是由Analyzer来做的。Analyzer类是一个抽象类,它有多个实现。针对不同的语言和应用需要选择适合的Analyzer。Analyzer把分词后的内容交给IndexWriter来建立索引。
所有的搜索引擎的目标都是为了用户查询。通过查询页面,输入关键字,提交给系统,程序就开始处理,最后把结果以列表的形式显示出来。在用Lucene的搜索引擎中,用到了Lucene提供的方法,可从所建立的索引文档中获得结果。
5 系统实现
5.1 开发环境
开发平台的选择:本系统的开发平台选择微软公司的.NET,开发工具采用ASP.NET。.NET是Microsoft面向Web服务的平台,由框架、Web服务、.NET企业服务器等几部分组成,提供涉及面较广、功能较全面的解决方案。数据库选择:根据需求分析选择了MSSQL Server 2000。
5.2 关键代码详解
5.2.1 代码结构
如图6:



![]()
![]() 写入 读取
写入 读取
![]()
![]()
![]() 生成
生成
![]()
![]()
![]()
引用

![]() 检索
检索
![]()
图6 代码结构
在网页爬虫Console端应用程序里输入一个有效的URL后这部份就开始从第一个URL开始遍历相关的链接并把相关的信息写入到网页数据存储数据库里,然后就由索引生成程序读取网页数据存储数据库,对每条记录生成索引记录,存放于生成的索引库文件里。生成索引需要调用Lucene.Net类。索引生成后在查询部分就能够在网页上输入关键字,对刚才抓取的信息的查询。并可以定位到信息的出处。下面对各部分关键代码进行详解。
5.2.2 爬虫部分
这部份的功能就是从输入的URL开始遍历各个相关的网页,它包括三个功能模块:网页抓取模块、网页减肥模块、爬虫维持模块。
首先定义一些变量用于保存抓取到的网页信息,urlList用于保存当前页面上的URL集合。然后根据全局变量url抓取此URL的网页信息到字节流变量里,经过转码后读取到变量PageString里,下步通过函数GetHttpUrl(PageString)对PageString中的URL标记进行提取并返回到urlList变量里,函数GetTitle(PageString)、parseScript(PageString)、parseHtml(PageString)、parseChar(Content)分别对网页信息变量获取标题、去除脚本块、去除HTML标记、去除特殊字符操作。再下步就是对获取到的标题、网页内容、链接等信息调用数据库操作通用类DAI保存到数据库里,这就实现了一个网页的抓取。再下步就是循环的对获取到的URL列表创建线程,针对每个URL来循环的执行上面的网页信息的抓取操作。