文件压缩与解压缩实践
摘 要
随着人们对数据的大量需求以及计算机使用时间的增加,计算机磁盘上的文件越来越大,越来越多。如何让有限的磁盘空间容纳更多的数据成为需要解决的问题。一方面,高速发展的存储技术以提高磁盘容量来解决这样的需求,但随着网络环境下数据传递的产生以及带宽的限制,大容量数据问题日益突出。在这两种需求的推动下,对数据压缩的需求产生了。人们可以将文件在不改变其本身的条件下,将其以更小的占用空间存储,并且在需要的时候将文件恢复成原有的样子,这就是压缩目的。本论文主要研究文件的无损压缩技术,并简要介绍了文件压缩的分类、几种常用的无损压缩格式和常用的压缩算法。运用LZ77字典算法、懒惰匹配算法和Huffman编码算法,使用Java语言在Jbuilder2006环境下设计了使用GZIP算法对文件压缩与解压缩的实现程序。用户可以根据自己的需求,使用此程序方便地对文件进行压缩或者解压缩操作。
关键词:压缩;解压缩;GZIP;Java
Practice of File Compression and Decompression
Abstract
As the great demand for data and the using time of computer are increasing, computer files on the disk grow more and more. How to make the limited disk space to store more data has became a problem crying out for solutions. On one hand, the rapid development of storage technology that can increase the disk capacity, can meet such demand. However, with the emergence of data transmission in a network environment and the bandwidth limitations, the problem of large-capacity data is increasingly prominent. With the promotion of both demands, the need for data compression and decompression is generated. People can store a file with a smaller storage space without changing the file’s own condition, and can restore the file; that is the purpose of data compression and decompression. This treatise principally research file lossless compression, otherwise, briefly introduced classification of file compression, some general lossless compression format and general compression algorithm. A procedure within algorithm called GZIP were designed for file compression and decompression in Java language under the circumstances of Jbuilder2006,which used LZ77 dictionary algorithm, lazy match algorithm and Huffman coding algorithm. Users could use this procedure compress or decompress files expediently according to their demand.
Key words: Compression; Decompression; GZIP; Java
目 录
论文总页数:21页
1 引言
1.1 课题背景
随着科学技术的进步,信息技术越来越广泛地应用到社会的各个行业和领域,互联网深刻地改变着人们的生活方式,推动着人类文明的进步。伴随着信息技术的普及和发展,互联网技术覆盖了社会政治、经济、文化、生产的各个领域,这种普及日常生活和工作更加的方便、文化娱乐方式更加的多样化。但是,在信息技术的飞速发展下,文件的信息量不断增加的背景下,文件的存储和拷贝要求能够保持数据的意思不变的情况下缩小容量,这就需要有压缩与解压缩来实现这个过程。本论文通过对一种压缩与解压缩方法的实践,对这种算法的实现过程进行研究。
1.2 国内外现有的研究成果
文件压缩格式现在已有许多种,最流行的有如下几种:
ZIP:我们可以利用WinZip对ZIP文件进行解压、释放等操作,还可以用它来处理ARJ、ARC、CAB、LZH等多种不同格式的压缩文件,从而大大地方便了用户的操作。
RAR:是一种高效快速的文件压缩格式,但不被大多数文件压缩程序支持,WinRAR是在Windows下处理RAR格式文件的最好工具。
ARJ:由DOS下曾经红极一时的压缩软件ARJ压缩而成的文件格式,它具有功能强大、压缩率高等优点。到了现在的Windows时代,它已经没有了往日的辉煌。
CAB:是Windows 98新增的一种特殊压缩文件格式,主要用于对有关软件安装盘中的文件进行压缩,其特点是压缩率非常高(可能是目前最高的),但一经压缩就不能再进行任何增加、删除、替换等修改,也就是说它的压缩包具有“只读”属性。我们也可使用WinZip对CAB压缩包进行操作。
UU/UUE:汉字编码方式,它们原本是Unix系统中使用的一种编码方式,后来被改写到DOS中,我们在传送中文邮件时只须事先使用该方式进行编码,此后就能顺利通过只能处理7位编码的邮件服务器,从而解决了汉字的传输问题。
ACE:一种新式的压缩程序,压缩比很高。
以上的压缩格式是可逆的,在解压缩之后,可以将被压缩的文件还原成以前未压缩的文件。另外还有一种不可逆的压缩格式,如MP3、MPEG、JPG等音频、视频、图像格式的文件都采用了这种压缩技术,从理论上来说它们也应该算压缩文件,不过它们所采用的压缩方式与前面讲的并不相同,这里简单地介绍一下:
JPEG:JPEG 全名为 Joint Photographic Experts Group,它是一个在国际标准组织(ISO)下从事静态影像压缩标准制定的委员会。它制定出了第一套国标静态影像压缩标准:ISO 10918-1 就是我们俗称的JPEG了。由于JPEG优良的品质,使得它在短短的几年内就获得极大的成功,目前网站上80%的影像都是采用JPEG的压缩标准。
JPEG 2000:正式名称为“ISO 15444”,同样是由JPEG组织负责制定。JPEG 2000与传统JPEG最大的不同,在于它放弃了JPEG所采用的以离散余弦转换为主的区块编码方式,而改以小波转换为主的多解析编码方式。其压缩率比JPEG高约30%左右,同时支持有损和无损压缩,无损压缩对保存一些重要图片十分有用。
MP3:MP3全称是MPEG 1 Layer 3,是一种高性能的声音压缩编码方案,它可以做出超小“体积”的音乐文件,大小只是原始音频数据的1/10到1/12。但人耳听起来,效果却没有太大差异。
MPEG:MPEG是Moving Pictures Experts Group(动态图像专家组)的缩写。现在使用的有4个版本:MPEG-1、MPEG-2、MPEG-3、MPEG-4。
2 压缩与解压缩程序分析
2.1 需求分析
文件的压缩与解压缩,要能方便地进行,要完成的功能包括压缩功能,解压缩功能,选择文件路径,选择操作方案,选择新文件保存路径。此程序还要在压缩成功后显示被压缩文件的大小,并对非法操作给出提示。
用户可以选择文件进行压缩或解压缩操作,并选择生成保存路径,默认的保存路径为原文件目录,压缩的生成文件以原文件加.gzip后缀命名,在解压缩操作中,若输入文件不是gzip格式的压缩文件,则提示gzip文件格式不对。
程序的基本设计原则有:方便性原则、功能实用性原则和开放性原则等。程序设计时采用较好的压缩技术,能保证文件压缩的压缩比和可恢复性,确保程序有较长的生命周期。
本程序的总体目标是实现文件压缩与解压缩的便捷操作,因此需要有便捷的操作界面。
2.2 使用的算法理论
2.2.1 LZ77算法简介
这一算法是由Jacob Ziv和Abraham Lempel于 1977 年提出,所以命名为LZ77。这种算法模型也被称为“滑动字典”模型或“滑动窗口”模型。
压缩的模型如图1:

图1 压缩中的LZ77算法模型图
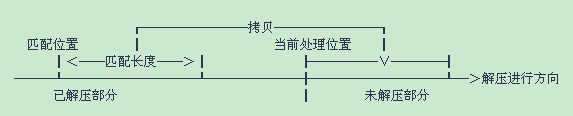
在最远匹配位置和当前处理位置之间是可以用来查找匹配的“字典”区域,随着压缩的进行,“字典”区域从待压缩文件的头部不断地向后滑动,直到达到文件的尾部,短语式压缩也就结束了。
解压缩的模型如图2:
2.2.2 Huffman算法简介
David Albert Huffman(哈夫曼/赫夫曼/霍夫曼)在MIT攻读博士学位期间于1952年提出了一种从下到上的编码方法,现在被称为Huffman编码,它是一种统计最优的变码长符号编码,让最频繁出现的符号具有最短的编码。
Huffman编码的过程具体编码步骤为:
(1)将符号按概率从小到大顺序从左至右排列叶节点;
(2)连接两个概率最小的顶层节点来组成一个父节点,并在到左右子节点的两条连线上分别标记0和1;
(3)重复步骤2,直到得到根节点,形成一棵二叉树;
(4)从根节点开始到相应于每个符号的叶节点的0/1串,就是该符号的二进制编码。
由于符号按概率大小的排列既可以从左至右、又可以从右至左,而且左右分枝哪个标记为0哪个标记为1是无关紧要的,所以最后的编码结果可能不唯一,但这仅仅是分配的代码不同,而代码的平均长度是相同的。
编码式压缩利用各个单字节使用频率不一样的倾向,使定长编码变为不定长编码,给使用频率高的字节更短的编码,使用频率低的字节更长的编码,起到压缩的效果。由于Huffman编码为根结点到叶子结点路径上的0和1的序列,而一个叶子结点的路径不可能是另一个叶子结点路径的前缀,因此一个Huffman编码不可能为另一个Huffman编码的前缀,这就保证了Huffman编码是可以区分的。由于用Huffman算法建立起来的树总是一棵最优二叉树,因此这又让Huffman编码能够实际应用到压缩中。
2.2.3 GZIP算法原理分析
GZIP使用deflate算法进行压缩。zlib,以及图形格式png,使用的压缩算法也是deflate算法。GZIP对于要压缩的文件,首先使用LZ77算法的一个变种进行压缩,对得到的结果再使用Huffman编码的方法(GZIP根据情况,选择使用静态Huffman编码或者动态Huffman编码)进行压缩。LZ77算法和Huffman编码结合起来,就是deflate算法的根本实现方法,也就是GZIP的压缩原理。
懒惰匹配(lazy match)是GZIP中对LZ77算法的改进,实现过程如下:
在压缩过程中,对于当前字节开始的串,寻找到了最长匹配之后,GZIP并不立即决定使用这个串进行替换。而是看看这个匹配长度是否满意,如果匹配长度不满意,而下一个字节开始的串也有匹配串的话,那么GZIP就找到下一个字节开始的串的最长匹配,看看是不是比现在这个长。这就是懒惰匹配。
如果比现在这个长的话,将不使用现在的这个匹配。如果比现在这个短的话,将确定使用现在的这个匹配。发现第二次匹配的匹配长度大,就不使用第一次的匹配串。如果直接使用第一次匹配的话,有可能将错过更长的匹配串。
在满足懒惰匹配的前提条件下,懒惰匹配不限制次数,一次懒惰匹配发现了更长的匹配串之后,仍会再进行懒惰匹配,如果这次懒匹配,发现了更长的匹配串,那么上一次的懒匹配找到的匹配串就不用了。
进行懒惰匹配是有条件的。进行懒惰匹配必须满足两个条件,第一,下一个处理字节开始的串,要有匹配串,如果下一个处理字节开始的串没有匹配串的话,那么就确定使用当前的匹配串,不进行懒惰匹配。第二,当前匹配串的匹配长度,GZIP不满意,也就是当前匹配长度小于max_lazy_match(max_lazy_match在固定的压缩级别下,有固定的值)。
2.3 开发环境
使用JBuilder2006进行程序开发。JBuilder是一个可视化JAVA开发工具。它是在Java2平台上开发商业应用程序、数据库、发布程序的优秀工具。它支持J2EE,所以程序员可以快速的转换企业版Java应用程序。使用此开发工具可以实现程序的可视化。
3 总体设计
系统总体结构设计是系统设计过程中及其重要的一步,对系统的技术层次,开发过程,功能实现及开发成本方面具有重大的影响。系统总统结构设计应尽可能的考虑人机关系,环境条件以及算法的可行性等的联系,使系统每个部分都能协调适应。
本实验论证是基于GZIP算法理论体系的,因此使用的压缩方法是参照GZIP算法的。GZIP算法理论体系主要包含三个内容:LZ77算法,Huffman算法,懒惰匹配算法。因此在设计过程中要注意如何实现这三个算法并且将其结合起来。
3.1 程序功能模块
根据设计思路,文件的压缩和解压缩是两个相反的操作,程序可分为GZIP压缩模块、UNGZIP压缩模块。现在设计出功能结构图如图3。
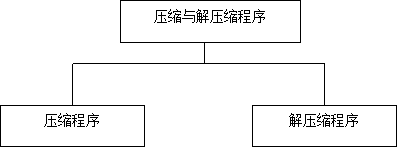
图3 功能结构图
3.2 模块分析与流程图
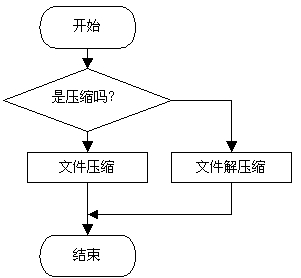
分析程序的总体流程图可以以图4来表示:
![]()
![]()
图4 总体流程图
压缩模块的实现流程为:
(1)打开要压缩的文件,使用字典算法扫描文件统计文件使用的字符集并统计每个字符集的使用次数。
(2)根据扫描的结果构建文件字符集的Huffman树。
(3)由文件的Huffman树求字符集中各字符的编码,形成Huffman编码表。
(4)建立压缩文件。
(5)将要压缩文件的字符集大小和文件的大小写入压缩文件。将字符集的Huffman树写入压缩文件,供解压缩时使用。
(6)从文件中读取一个字符集,查Huffman编码表,得到它的Huffman编码。按位流放入压缩文件的写缓冲区。
(7)检查压缩文件的写缓冲区,如果已满一个字节,写入压缩文件,如果要压缩的文件没有达到文件的结尾,转到步骤6。
(8)关闭要压缩文件和压缩文件
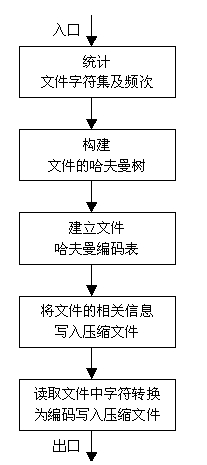 画出流程图如图5:
画出流程图如图5:
图5
图5 压缩模块流程图
解压缩模块的实现流程为:
(1)打开压缩文件,读取字符集字符个数和文件的字节数。读入文件的Huffman树。
(2)建立解压缩文件。
(3)读入一个字节的编码,用Huffman树得到字符,将字符写入解压缩文件,如果编码已用完,就读取下一个字节,如此重复,直到读取压缩文件的全部编码。
(4)关闭压缩文件和解压缩文件。
画出流程图如图6:
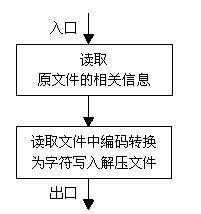
图6 解压缩模块流程图
3.3 程序中各个类的初步定义
为了完成此程序,应当设计一个接口,十四个类,和二个异常处理类。其中
接口:Checksum。
类:Adler32;CRC32;CheckedInputStream;CheckedOutputStream;Deflater;DeflaterOutputStream;GZIPInputStream;GZIPOutputStream;Inflater;InflaterInputStream;ZipEntry;ZipFile;ZipInputStream;ZipOutputStream。
异常索引:DataFormatException;ZipException。
各个类的简单介绍如表1:
表1:程序各个类的作用
|
条目 |
类型 |
描述 |
|
Checksum |
接口 |
被类Adler32和CRC32实现的接口 |
|
Adler32 |
类 |
使用Alder32算法来计算Checksum数目 |
|
CheckedInputStream |
类 |
一个输入流,保存着被读取数据的Checksum |
|
CheckedOutputStream |
类 |
一个输出流,保存着被读取数据的Checksum |
|
CRC32 |
类 |
使用CRC32算法来计算Checksum数目 |
|
Deflater |
类 |
使用ZLIB压缩类,支持通常的压缩方式,程序核心类 |
|
DeflaterOutputStream |
类 |
一个输出过滤流,用来压缩Deflater格式数据 |
|
GZIPInputStream |
类 |
一个输入过滤流,读取GZIP格式压缩数据 |
|
GZIPOutputStream |
类 |
一个输出过滤流,读取GZIP格式压缩数据 |
|
Inflater |
类 |
使用ZLIB压缩类,支持通常的解压方式,程序核心类 |
|
InflaterInputStream |
类 |
一个输入过滤流,用来解压Inflater格式的压缩数据 |
|
ZipEntry |
类 |
存储ZIP条目 |
|
ZipFile |
类 |
从ZIP文件中读取ZIP条目 |
|
ZipInputStream |
类 |
一个输入过滤流,用来读取ZIP格式文件中的文件 |
|
ZipOutputStream |
类 |
一个输出过滤流,用来向ZIP格式文件口写入文件 |
|
DataFormatException |
异常类 |
抛出一个数据格式错误 |
|
ZipException |
异常类 |
抛出一个ZIP文件 |
4 详细设计和实现
压缩程序的实现过程中,涉及到很多类的调用,除了压缩有关的类,还有IO类。对于IO类的调用不考虑的情况下,各个压缩功能类的调用流程(如图7):
(1)主程序gzip调用输出过滤流GZIPOutputStream,读取GZIP格式压缩数据,压缩开始。
(2)GZIPOutputStream调用CRC32来计算Checksum的数目。
(3)在CRC32返回结果后,GZIPOutputStream调用Deflater压缩类来进行压缩。在Deflater类的调用过程中,实现了对数据的压缩字符集确定与编码,也就是实现了LZ77算法、懒惰匹配与Huffman编码的结合。
(4)建立压缩文件,调用DeflaterOutputStream来压缩Deflater格式数据。
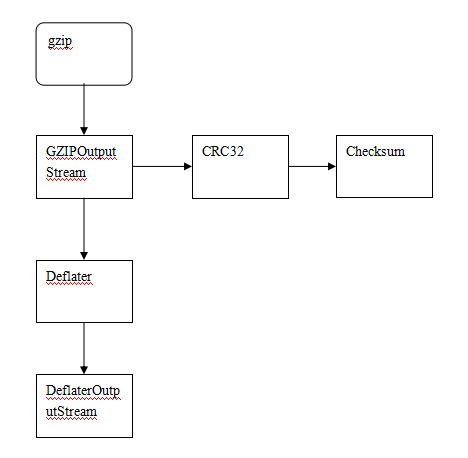
图7 压缩类的调用顺序图
这些过程的操作是不能离开IO类的,所以实现这些过程的前提是要有数据流输入,也就是调用FileInputStream,打开需压缩文件作为文件输入流;在以上的流程完毕之后,调用FileOutputStream类建立压缩文件输出流,最终形成压缩后的文件。